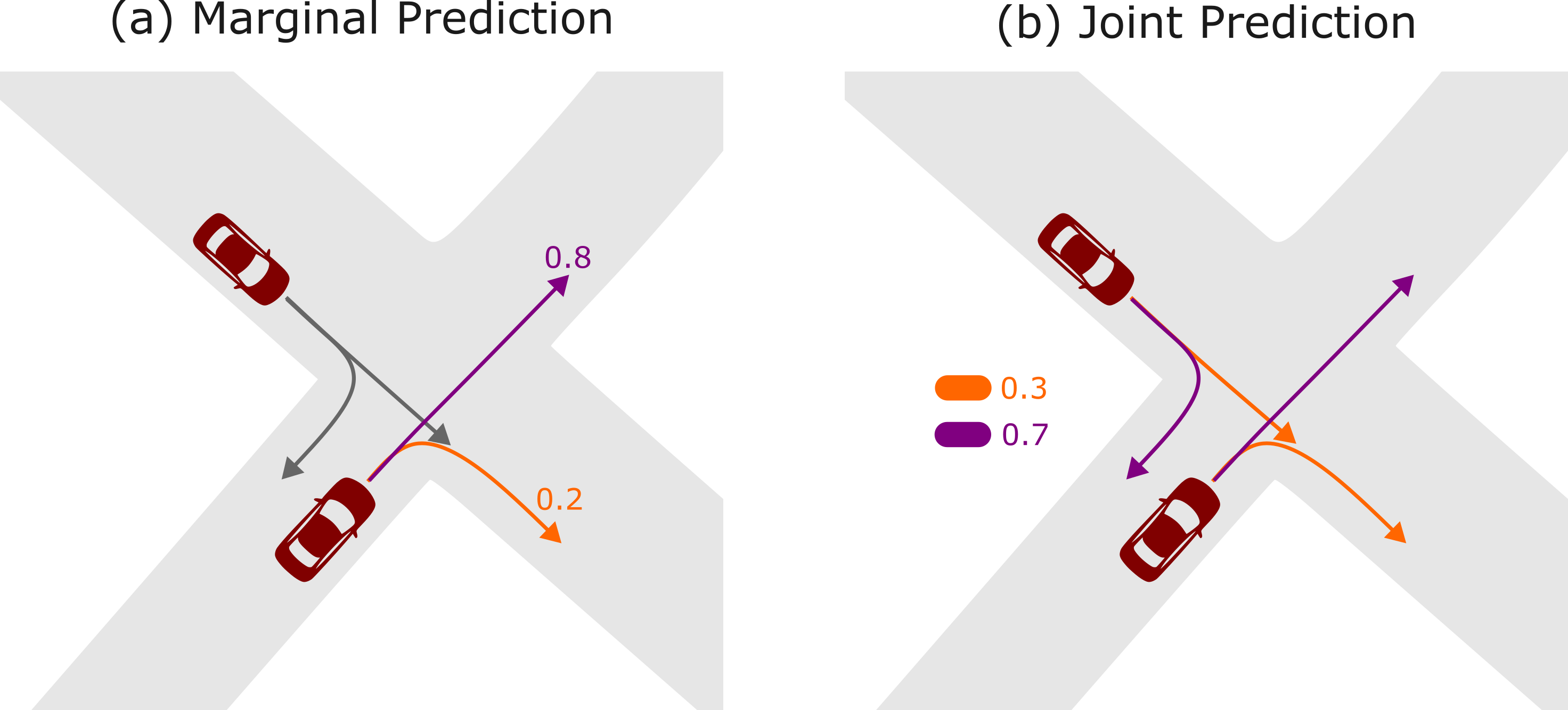
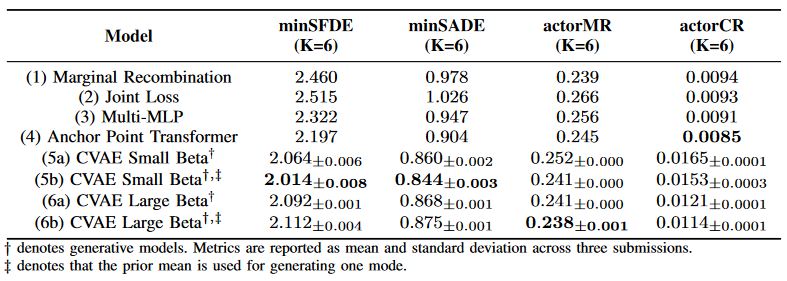
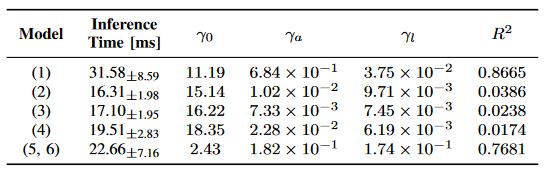
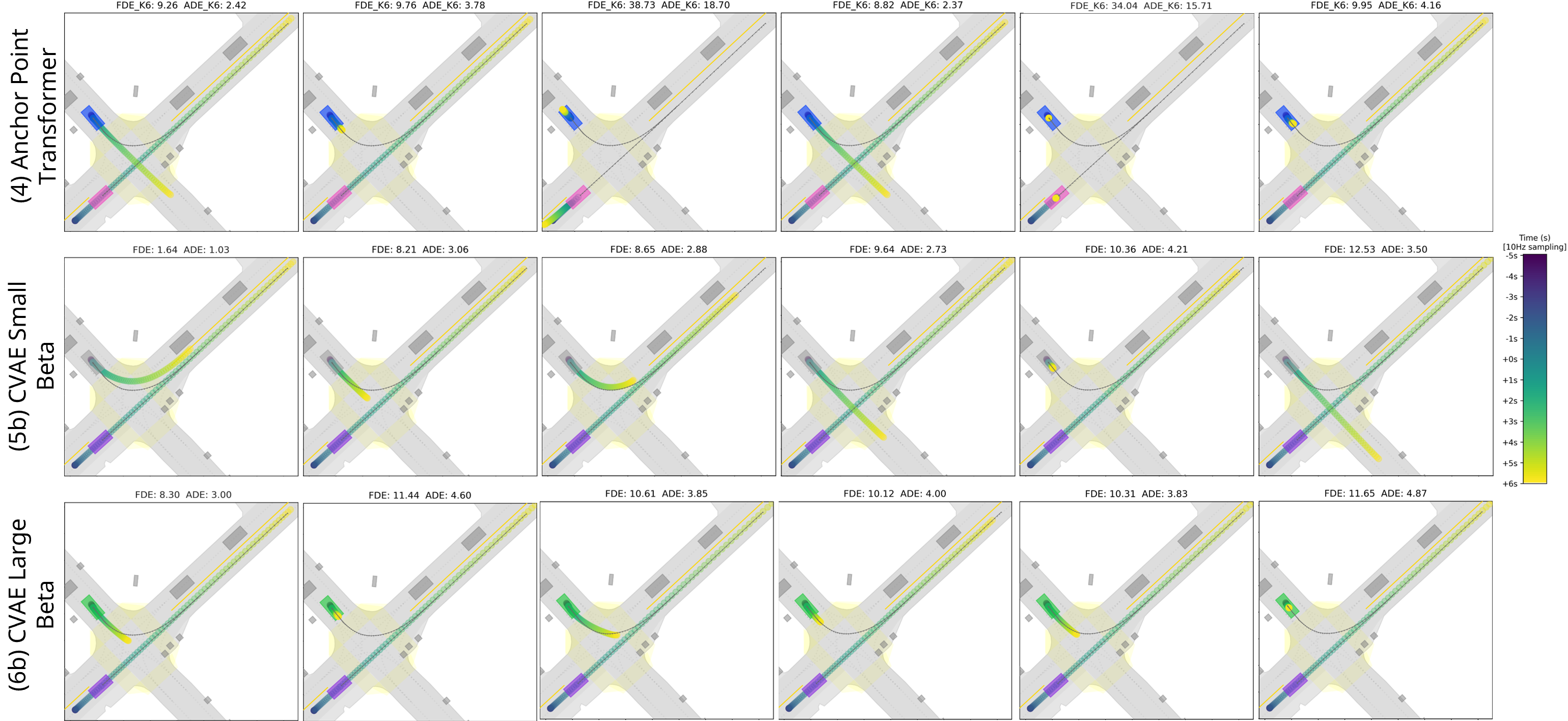
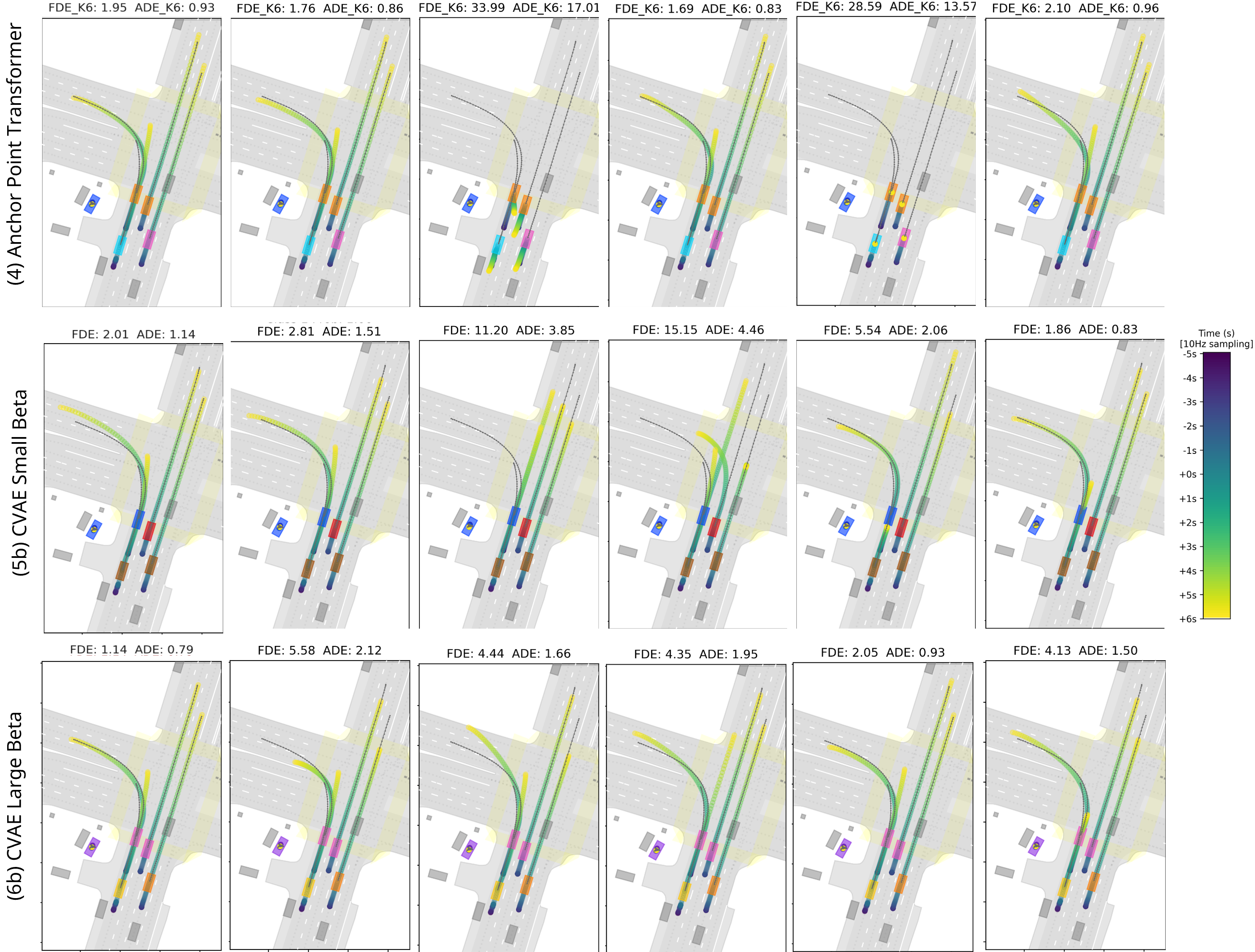
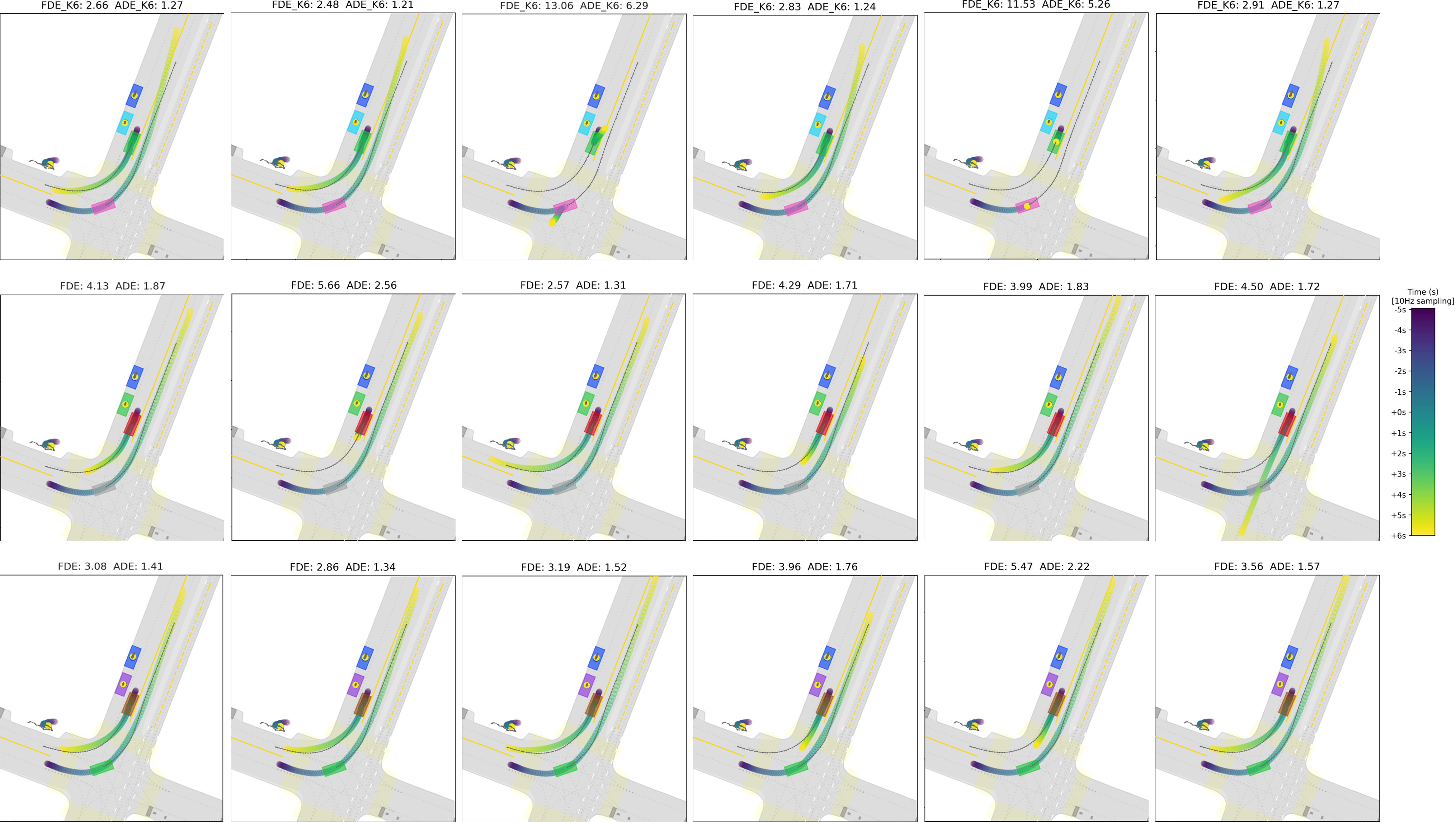
Accurate motion prediction of surrounding traffic participants is crucial for the safe and efficient operation of automated vehicles in dynamic environments. Marginal prediction models commonly forecast each agent's future trajectories independently, often leading to sub-optimal planning decisions for an automated vehicle. In contrast, joint prediction models explicitly account for the interactions between agents, yielding socially and physically consistent predictions on a scene level. However, existing approaches differ not only in their problem formulation but also in the model architectures and implementation details used, making it difficult to compare them. In this work, we systematically investigate different approaches to joint motion prediction, including post-processing of the marginal predictions, explicitly training the model for joint predictions, and framing the problem as a generative task. We evaluate each approach in terms of prediction accuracy, multi-modality, and inference efficiency, offering a comprehensive analysis of the strengths and limitations of each approach.